이 글은 루씬에 대한 소개글입니다.

안녕하세요 정우현입니다.
오늘은 엘라스틱 서치의 본체라고 할 수 있는 루씬에 대해서 소개하려고 합니다.
그 과정에서 아래와 같이 세 가지 내용을 다룰 생각입니다.
- 왜 루씬이 엘라스틱의 본체라고 이야기하는지
- 루씬에서 인덱싱은 어떻게 이뤄지는지
- 검색을 하는 방식은 어떻게 되는지
루씬이 사실 본체다
저는 엘라스틱 서치가 루씬을 베이스로 만든 검색엔진이라고 했을때 루씬이 어떤 역할인지 몰랐습니다.
"엘라스틱 서치 내부에서 루씬이 가벼운 역할을 하나보다" 이정도로만 생각했습니다.
하지만 괜히 엘라스틱 서치 위키피디아에 "based on lucene library"라고 바로 나와있는게 아니었습니다.
사실 엘라스틱 서치는 루씬이 본체입니다. 엘라스틱 서치는 루씬을 분산형으로 만들어서 사용할 수 있게 만든 검색엔진입니다.
트래픽이 몰려서 색인과 검색에 필요한 자원이 많아진다면 어떤 프로그램이던 한대의 컴퓨터로 부담하는데에는 한계가 있습니다.
루씬은 이런 분산처리를 구현하지는 않았기 때문에, 이 루씬을 이용해서 분산 처리를 구현하고 더 나아가서 검색엔진으로 발전된 것이 엘라스틱 서치입니다. 엘라스틱 서치는 인덱싱과 데이터를 샤딩, 레플리케이션하여 여러 컴퓨터에 분산해서 처리를 해주는 것이죠.
루씬이 인덱싱 하는 방법
루씬의 인덱스는 아래 그림과 같이 inverted index를 사용합니다.
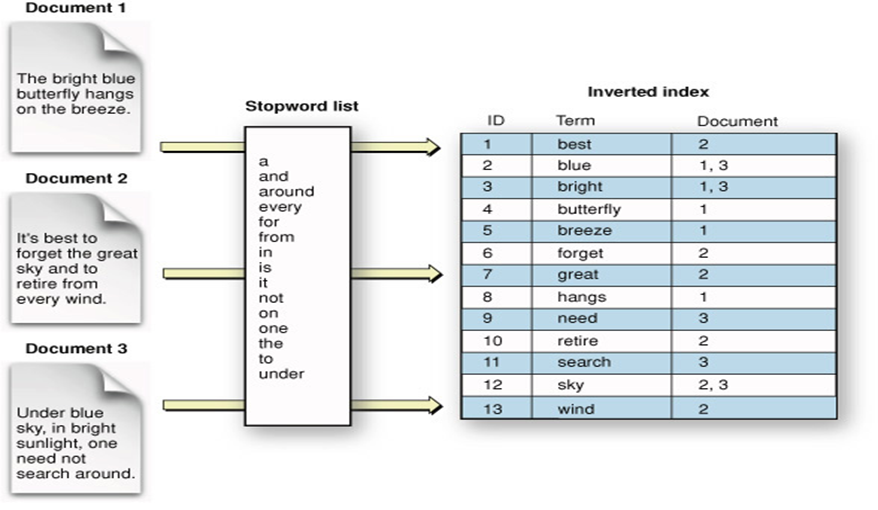
이 인덱싱을 하는 과정에서 루씬은 문서나 이메일, 웹페이지, 데이터베이스 내부의 튜플등의 문서를 Document로 만들어서 문서를 파싱합니다. 파싱을 하면 우리가 봤을때에는 단어로 인식되는 토큰이라는 단위로 정보를 분석하게 됩니다. 이 토큰이 위 사진에서 term에 속하게 되고, 사진에서는 해당 토큰을 포함했던 문서라면 토큰을 만들어주고 있습니다. 그러면 해당 키워드로 검색이 가능해지겠죠.
+ 이때 인덱싱을 하고 토큰 파싱을 하는데에는 여러가지 분석기를 사용할 수가 있습니다. 나중에 이 분석기를 세팅하는 작업을 하게 되면 공유하도록 하겠습니다.
쿼리의 방법
이제 루씬이 검색하는 방법에 대해서 이야기를 하려고 합니다. 우리가 검색하는 모습을 보면 처음에는 구글이나 네이버같은 검색사이트의 검색창에 문장이나 단어를 넣어 검색을 시작합니다. 그리고나서 원하는 문서를 못 찾으면 작성 일자나 필수 키워드등을 더 추가해서 검색합니다. 이때 루씬은 그 조건들을 쿼리로 만들어서 검색을 진행합니다. 그렇다면 검색은 어떻게 이뤄질까요?
검색을 진행하는 방법으로 루씬은 다음과 같은 순수 불리언 모델과 벡터 공간 모델을 통해 검색을 합니다.
1. 순수 불리언 모델
문서에 검색어가 있으면 검색 결과로 바로 뽑아주는 방식입니다. 문서에 쿼리 결과가 있는지 여부만 확인하는 방식이기 때문에 우선순위라던가, 검색어와의 연관성이 얼마나 일치하는지는 알 수 없습니다.
2. 벡터 공간 모델
벡터 공간 모델은 쿼리와 문서를 고차원 벡터로 표현해서 벡터간의 거리를 계산해서 유사도를 뽑아내는 방법입니다. 예를 들어서 King이라는 단어는 Dominator + Male과 같은 벡터일 수 있고 King에서 - Male + Female 과 같이 벡터 연산을 해주면 Queen과 같은 방식으로 쿼리나 문서를 표현할 수 있게 됩니다. 이 벡터를 잘 찾아내기 위해서 요즘은 NLP도 하고있죠.
글을 마무리하면서
이번 글에서는 루씬에 대해서 소개를 해봤습니다.
루씬 인 액션 1장에 나오는 내용이었습니다. 이 다음부터는 루씬을 직접 굴려보면서 얻었던 경험을 공유해보면 더 좋을 것 같습니다.
:)