이 글을 쓰는 목적
코틀린 스프링을 사용하는 이유
코틀린 스프링을 백엔드 개발할때 쓰는 이유를 적은 글을 쓰며 백엔드 개발을 시작할때 최근에 가장 많이 논의되는 언어가 코틀린과 타입스크립트라고 생각을 하고 있는데, 개인적으로는 서로
blog.mayleaf.dev
스프링 MVC, 스프링 웹플럭스 두 생태계가 있는데 MVC는 멀티쓰레드 기반이고, 웹플럭스는 그러면 왜 쓰는걸까요?
오늘은 웹플럭스를 사용 하는 이유를 공유해보고자 이 글을 씁니다.
이 글의 내용
"스프링 웹플럭스" 쓰는 이유가 뭐냐고 물어보면 저는 리액티브 프로그래밍을 하기 위해서 사용한다고 이야기할 것 같습니다.
그래서 리액티브 프로그래밍이 무엇인지, 왜 스프링 웹플럭스를 사용하는지를 적었습니다.
본문
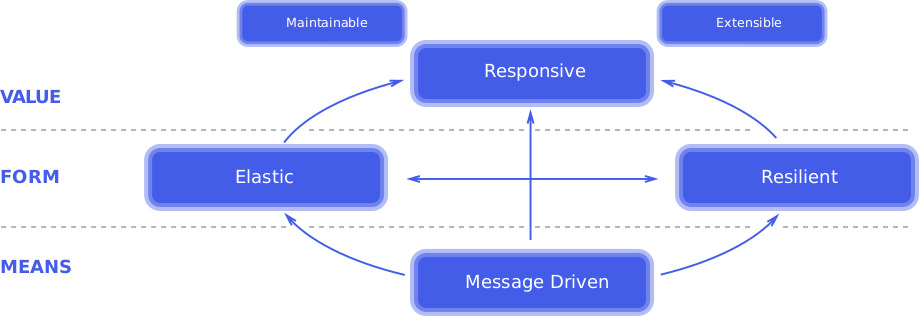
위 그림은 리액티브 선언문에서 발췌해서 가져왔습니다.
메시지를 사용해서 탄력적이고 회복이 잘되는 즉각적 응답 시스템이라고 축약할 수 있는데, 사실 이 내용은 직접 찾아보시는게 더 좋을 것 같습니다.
중요한건 왜 스프링 웹플럭스를 쓰냐인 것 같습니다.
@GetMapping("/numbers")
fun numbers(): Flux<Int> = Flux.range(1, 5)
.doOnNext { println("Number $it") }안 익숙하신 분들을 위해서 위 코드를 잠깐 설명하면 Flux는 복수의 데이터를 다루는 스트림입니다.
range를 통해서 1,2,3,4,5라는 데이터를 순차적으로 내려주고(기본적으로 순차적으로 흐릅니다)
Next가 호출될때 println을 해주는 코드입니다.
우선 함수를 doOnNext에 넘겨주면서 비동기적으로 동작하는 것을 확인할 수 있었습니다.그리고 여기에서 flatMap과 같은 연산자를 통해서 새로운 publisher를 만들고 논 블락킹하게 동작하게 하는등 비동기 논블락킹한 방식으로 개발할 수 있습니다.
그러나
그게 스프링 웹플럭스를 써야할 이유는 되지 않습니다. 이런 리엑티브 패러다임은 이미 Rx라이브러리를 통해서 대부분의 언어에서 접할 수 있고, 비동기적으로 동작하는 방식은 거의 모든 언어에서 지원해줍니다.
리액티브 프로그래밍할때 스프링 웹플럭스를 쓰는 이유는 결국 스프링 생태계 때문입니다. 비동기, 논블락킹, 배압처리 다른 프레임워크나 언어에서도 지원해줍니다. 단지 "리액티브"한 시스템을 만들려면 단순 언어와 프레임워크만으로는 직접 구현해야하는게 많고 그 시스템에 필요한 것들을 개발할때 일관적으로 대부분의 기능을 개발할 수 있게 해주는게 스프링의 생태계일 뿐입니다.
일례로 우리가 리액티브한 "시스템"을 개발해본다고 생각해볼까요? 전제 시스템중 어떤 모듈 서버A가 죽었습니다.(어떤 이유로든 항상 죽을 수 있음) 그리고 서비스 B는 어떤 이벤트를 받으면 A를 호출해야합니다. (물론 리엑티브 패러다임에 따르면 이벤트를 던지고 이걸 A가 받아서 처리를 해줘야하는 거지만)이 서버 A가 외부 연동 서비스라고 생각해봅시다.어떻게 하면 가장 빠르게 A가 살아나는 것을 기대할 수 있을까요? A가 살아날때까지는 좀 요청을 덜 보내야하지 않을까요? 물론 다른 외부 연동 서비스 개발자분들이 잘 개발해주실것이라고 믿지만, 웜업되기전에 막 살아난 서버를 요청하면 다시 뻗기 일수일 것입니다.
이런 상황에서 A가 살아날때까지 기다리려면 스프링에서는 resilience4j를 쓰면 됩니다. spring circuitbreaker를 의존성에 추가하면 적용됩니다. 슬라이딩 윈도우를 적용해서 일정이상의 호출이 문제가 발생하면 해당 동작을 다른 흐름으로 보낸다던가 하는 방법들을 적용하게 해줄 수 있죠. Next 호출을 멈추는 것만 해도 벌써 큰 문제가 해결되었을 것입니다. 그리고 이런 기능들은 제가 찾아본 바에선 다른 프레임워크 생태계에 바로 들어와있는 경우는 찾지 못했습니다(별도 라이브러리들로는 존재). 이런 스프링 생태계는 쉽고 편하고 빠르게 다른 외부 서비스에 미치는 영향을 확 줄일 수 있었습니다. 배치를 돌리다가 장애가 나서 다시 돌리던 부분부터 돌리려면, 스프링 생태계에서는 그냥 스프링 배치쓰고, 돌리던 컨텍스트에서부터 다시 돌리면 됩니다.(병렬적으로 진행하던 경우 제외)
리액티브는 언어와 프레임워크가 해결해주는게 아니다.
제가 이야기하고 싶었던건, 리액티브 선언문을 잘 지키기 위해서는 결국 리액티브한 "시스템"이 갖춰져야한다는 것이었습니다. 메시지 큐에 백날천날 던져봐야 카프카 브로커가 메모리 부족해서 다 뻗어버리면 리액티브할 수 없겠죠?
서버가 아무리 비동기, 논블락킹으로 데이터를 처리해준다고 해도 CPU, 메모리에 한계는 옵니다. 그러면 서버 노드를 늘리거나 파드를 더 할당시켜줘야겠죠? 아니면 초당 20만건이상 한 레디스에 부하가 간다면, 아마 높은 확률로 터질거라고 생각합니다. 그러면 replica를 더 만들어서 분배시켜주거나, 쓰기작업이 그렇게 많은 것이라면 센티넬이나, 클러스터 시켜줘야겠죠?
이런 작업들이 부하 수준에 의해서 자동으로 이뤄지지 않으면 결국 어느 한 구석에서는 SPOF가 생길 것입니다.
그렇기 때문에 "스프링 웹플럭스쓰면 리액티브한 백엔드를 갖출 수 있어."라고 생각하면 안됩니다.
뭘 어떤 프레임워크를 쓰던 사실 절대 이건 해결이 안되구요. 자동화된 Ops가 함께 갖춰져야만 진짜 리액티브한 백엔드가 갖춰질 수 있습니다. 정리하면 사실 배압때문에, 비동기때문에, 넌블락킹을 해줘서 스프링 웹플럭스를 쓴다기보다는 스프링 생태계가 백엔드 시스템을 갖추기 위해 필요한 대부분(거의 모든이라고 해도 과언이 아니다 싶습니다)의 기능이 있기 때문에, 이런 시스템을 일관된 방식으로 개발하기 위해서 스프링 생태계를 채택하는것이고, 그중에서 리액티브하게 서버를 개발하기 위해서는 웹플럭스를 사용할 뿐이라고 생각합니다.
결론
리액티브하기 위해선 시스템이 모두 강건해야 합니다. 그리고 시스템을 모두 일관적인 방식으로 개발하기 위해서 하나의 생태계를 선택하는 것이라 생각합니다. 그리고 백엔드 시스템에 필요한 대부분의 모듈을 스프링 생태계에서 지원해주기 때문에 사람들은 스프링 생태계를 선택하는 것이고, 그중에서 리액티브하게 API 서버 개발을 하기 위해서 스프링 웹플럭스를 사용합니다.
리액티브 선언문이 나온지 벌써 10년이 지났습니다. 지금에 와서 리액티브에 대해서 논하는게 맞는 시간인가 싶지만, 시리즈물이므로 이해해주시면 감사하겠습니다. ㅋㅋ 다음 게시글은 아마 3월 24일 전에 하나 더 작성할 것 같습니다 :)
'Kotlin' 카테고리의 다른 글
| private 함수를 테스트하고 싶을때 (0) | 2024.03.20 |
|---|---|
| 테스트 하기 좋은 코드, 좋은 테스트 코드 (0) | 2024.01.15 |
| IR compiler란? (0) | 2024.01.04 |
| Error Stubbing 하기 (0) | 2023.12.21 |
| MockKInjects 및 Lateinit 사용을 통한 Kotlin 테스트 이슈 해결하기 (0) | 2023.12.13 |